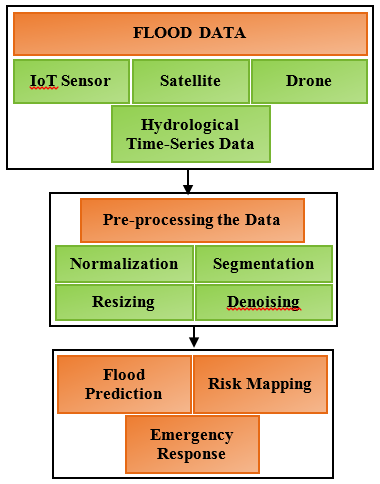
Floods are among the most distressing natural disasters that negatively impact coastal regions, especially in certain countries like India and China. India has a dense population, and seasonal cloudbursts strengthen their impacts. The government of India and other private organizations project various schemes and strategies to alert the people living in coastal areas and protect them from floods and related disasters. Several earlier research methods were anticipated to forecast the flooding information; still, their accuracy is low, and the false positive rate is high, which dissatisfies the public and makes them lethargic in critical scenarios. The accuracy of flood prediction is low because the data analytics methods have found that the real-time data obtained from coastal areas is unreliable. Also, they performed on any one of the data, such as satellite images or sensor readings, that are not enough to predict the real scenarios that are going to happen. Hence, this work has aimed to predict the real-time flood data generated using IoT-sensor networks, satellite images, drone footage, and hydrological time-series data, and improve the data quality by applying various robust preprocessing methods that can ensure high quality and actionable insights. This work systematically demonstrates a comprehensive group of preprocessing methods tailored for multi-modal flood data collected from several dangerous coastal areas of India. The dataset comprises spatial, temporal, and spatio-temporal data, where their quality is improved by applying normalization, segmentation, stationarity verifications, time-based feature collection, outlier detection, resizing, color conversion, image enhancements, denoising, and others. It prepares the data for further flood prediction and forecasting processes accurately, which helps people secure themselves by making immediate decisions. It qualitatively and quantitatively evaluates the data to assess the efficiency in increasing data quality and reliability. It also makes the computing models more accurate in flood prediction, risk mapping, and emergency response preparation. The experiment is carried out with a comprehensive multi-modal dataset, and the results are verified by the prediction accuracy using machine learning algorithms before and after preprocessing is applied. It shows that the models obtained the highest accuracy after preprocessing, and it insists that preprocessing is a significant task that can harness the full efficiency of learning models and geospatial analytics in disaster management. It also concludes that preprocessing is a crucial task that needs to be applied before any data analytics.
{kind=link}